
We saw how to get logs and crawl data with a complete guide to the OnCrawl API. This article will demonstrate how to work on your data on the segments that convert the most. There is already help on how to customize your segmentation with OnCrawl; the article is complete and gives many ways to do it.
Segmentation by URL is very important because it will apply to all your reports (Crawl Reports, Logs Monitoring, SEO Impact Reports, Ranking Reports…). It helps you understand how each group of pages behaves and focus your SEO analyses on the categories that include the pages that convert the most. By default, OnCrawl offers automatic segmentation on the first level of most representative URLs.
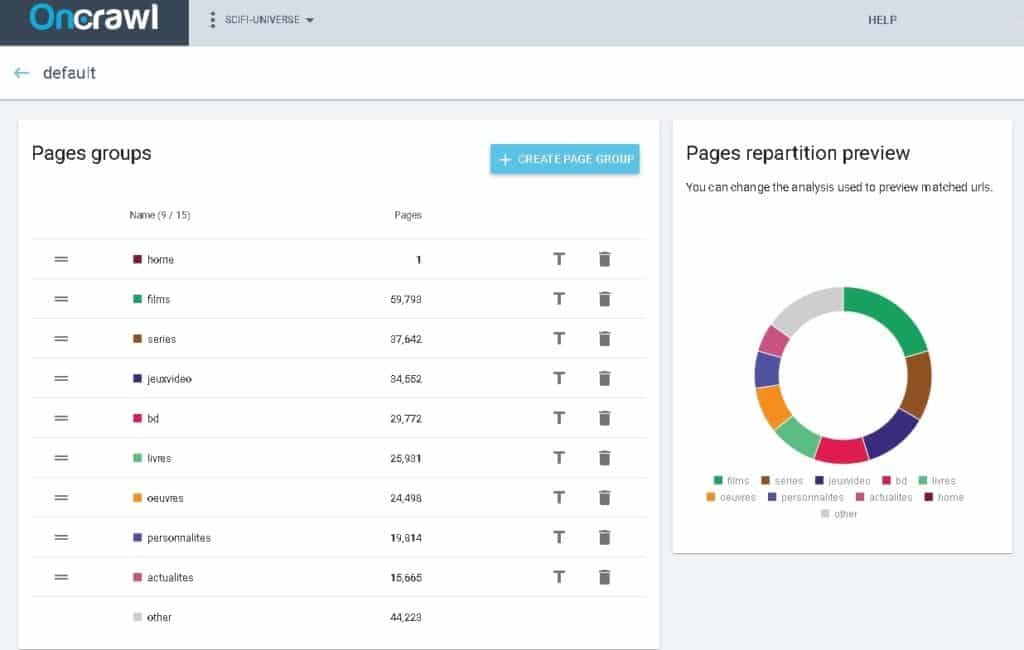
With this new R package, you will be able to create an advanced multi-level segmentation in less than 1 minute.
Configure your segmentation with OnCrawl
There are three ways to do this:
- “From existing set or import”: very useful for sharing a segmentation between projects or for importing a segmentation
- “From field automatically”: this is the frequency method, but limited to the first level within the URL
- “From scratch”: manual
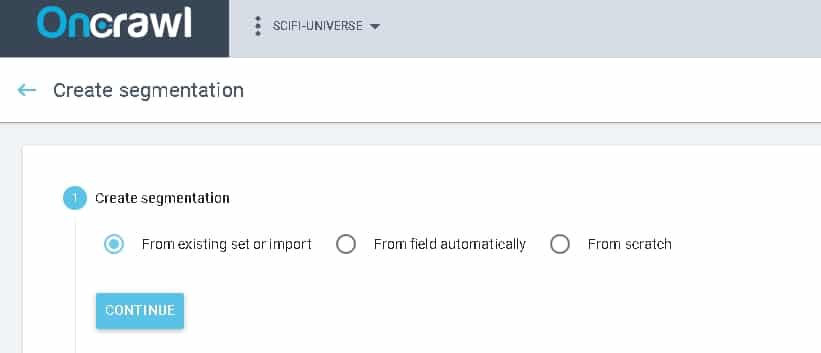
It is very important to build the most complete segmentation and update it each time new content is launched. We will use the “From existing” method which allows us to import a JSON file that will be generated by the R package “oncrawlR”.
There are three main approaches to segmenting URLs:
- If the URLs of the site are well-constructed, a frequency approach works very well
- If the URLs of the site are poorly constructed, an extraction from breadcrumbs on each page can be sufficient.
- If the site has all of its pages at the root of the URL without any organization, a grouping by semantic similarity will be the only solution.
We will focus on the first method.
Frequency clustering
The first step is to retrieve all the URLs of a crawl.
Solution 1
We saw the method with the OnCrawl package which allows to do it in 1 single line of code
pages <- listPages(crawlId)
Solution 2
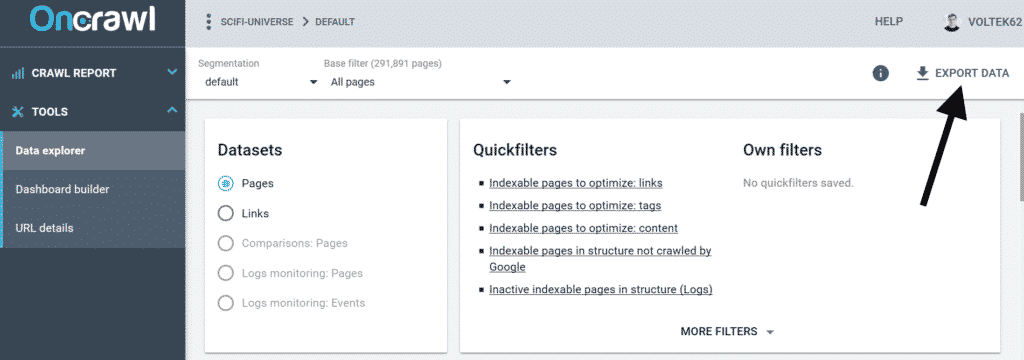
But you can also do it without the API with a simple export, which you can get at this address.
Then, you must execute the following R code to convert your data to the expected format. Be careful not to forget to replace the name of the CSV file (export-5acbcdefghi01399752c-custom_query.csv) with the name of your CSV file.
This method is only for users who do not have access to the API.
library(stringr)
library(dplyr)
library(readr)
export_custom_query <- read_delim("export-5acbcdefghi01399752c-custom_query.csv", ";", escape_double = FALSE, trim_ws = TRUE)
pages <- export_custom_query %>%
select(url) %>%
rename(urlpath = url ) %>%
mutate(urlpath= gsub("https://www.scifi-universe.com", "", urlpath))
Declination of all URLs
The objective is to decline all URLs in all their possible variants.
For example:
/Books/appearances/May-2019
becomes
– Books/appearances/May-2019
– Books/appearances/
– Books/
The most frequent segments will often be repeated. Sometimes there will be segments that do not exist, but they will be rare and therefore have not been included in our top 15.
In order to simplify the use, I created the oncrawlSplitURL function with a limit that you can set. It is important to choose the limit where you will stop your ranking. (Here, for example, we keep the first 25.)
top <- oncrawlSplitURL(logs$urlpath, 25)
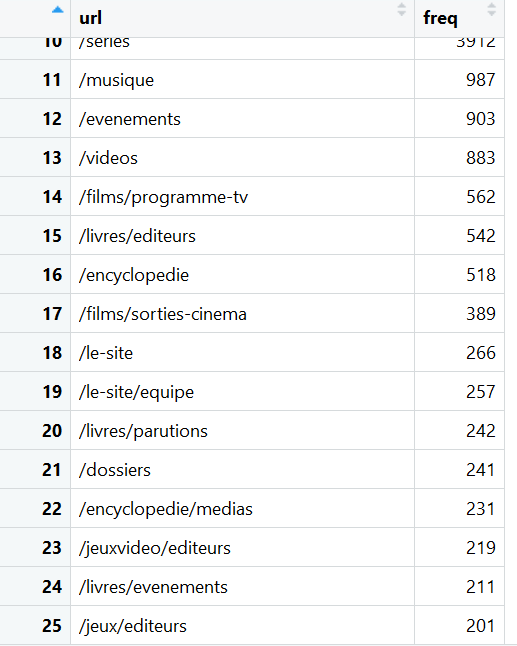
Here is the result in 1 line of code for a site with more than 300 000 URLs
Now, it is necessary to transfer this result to JSON format for OnCrawl taking into account complex conditions. For example, here, the “/le-site” segment does not contain the “/le-site/equipe” segment, which is detected as a separate segment.
Export a JSON file to Oncrawl
In the R package, there is now a function that will generate a JSON file that can be used directly by OnCrawl. For display purposes, OnCrawl is limited to a maximum of 15 segments. My code filters your ranking to the top 15.
With the following line, you will create a file named “oncrawl_frequency.json” at the root of your project:
oncrawlCreateSegmentation(top$url,"oncrawl_frequency.json")
There are then 2 methods to integrate it into OnCrawl.
Solution 1: Upload the generated JSON file
When you create your segmentation, click on “From existing set or import”. Then, you will need to choose “Upload File” and drag and drop the file “oncrawl_frequency.json” in the dedicated area.
Solution 2: Copy & paste JSON code
When you create your segmentation, click on “From existing set or import”. Then, choose “Paste JSON” and copy & paste the full JSON code from “oncrawl_frequency.json” into the dedicated area. Be careful not to forget brackets or braces; otherwise, it will not work.
For each solution, you will be able to instantly view the result and it will be ready to use for all your dashboards.
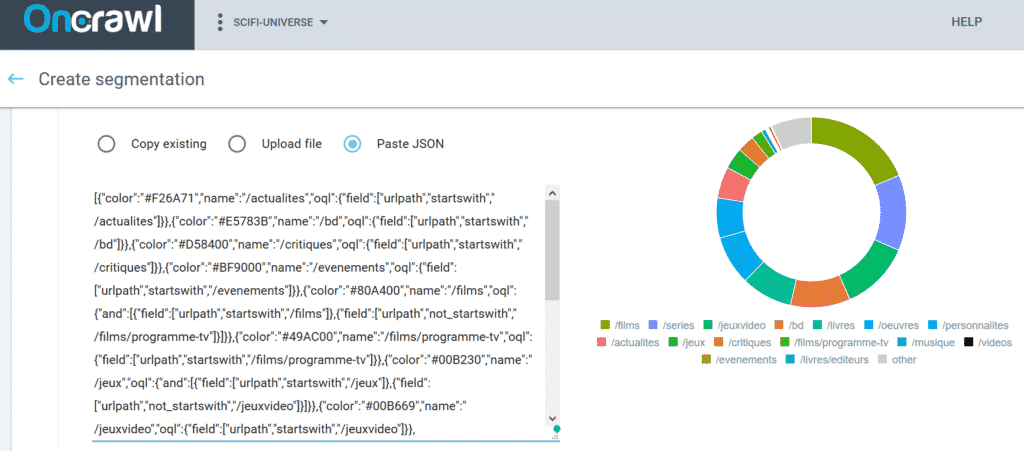
Mission accomplished
The configuration is ready!
The objective of this new R package is to save you valuable time in your analyses and above all to provide a multi-level segmentation. If you want to go even further, you can also take the number of conversions generated by your pages into account.
Now we have all the elements to use Machine Learning to discover all the metrics to monitor and to work on how to increase the crawl rate of Google’s bots. We’ll save that for next time.