
Since 2012, I have written some blog posts about Data & SEO with R language, but now, it is time to create a robust R package for SEO with Sparkler.
I have given ten talks in leading SEO events in 2017. What I have observed is although people find the exposed projects very interesting and useful, the cost of the tools API access prevent them from taking advantage of the solutions completely. But if you are a developer, you can use homemade and costless solutions for analyzing the SEO data of your website. Now, there are hundreds of Open Source Big Data tools out there. All of them promising to save you time, money and help you uncover never-before-seen business insights
Introduction
DIY 1: Deploy a crawler with OpenStack and Sparkler : https://github.com/USCDataScience/sparkler
The idea is to create a R package and explain my code with DYI blog posts.
The RSparkleR package installs Sparkler with OVH, automatically traverses and parses all web pages of a website, and extracts all data you need from them at once with five commands. The package can be used for a wide range of useful applications like web mining, text mining and web content mining.
Example for ovh.com ( you can download all dataset directly in RStudio )
Workflow :
- Create one instance with OVH Public Cloud for deploying Spark + Solr
- Launch a crawl with Sparkler
- Get data from Solr
- Categorize URL & Dashboard ( only for the advanced training with Remi: dataseolabs.com )
Yet another crawler?
A web crawler is a bot program that fetches resources from the web for the sake of building applications like search engines, knowledge bases, etc.
I need :
– more speed
– more scalable and efficient solution
– not to slow down my current machine with RStudio
– to import results instantly without waiting for the end of crawl and work directly with Dataiku, a powerful Data Science Platform.
State of the art
Open Source
- Scrapy is an open-source framework allowing the creation of indexing robots. Developed in Python, it has an active community, offering many additional modules.
- Apache Nutch is an initiative to build an open source search engine. It uses Lucene as a library of search and indexing engines.
Commercial
- Screaming Frog SEO Spider is a desktop program (PC or Mac) which crawls websites’ links, images, CSS, script, and apps from an SEO perspective.
- OnCrawl is a semantic web crawler for state of the art Enterprise SEO Audits. It helps you discover errors in HTML, linking structure and content that can be optimized.
New Open Source solution: Sparkler
Sparkler (contraction of Spark-Crawler) is a new web crawler that makes use of recent advancements in distributed computing and information retrieval domains by conglomerating various Apache projects like Spark, Kafka, Lucene/Solr, Tika, and pf4j.
Sparkler is an extensible, highly scalable, and high-performance web crawler that is an evolution of Apache Nutch and runs on Apache Spark Cluster.
- Supports complex and near real-time analytics
- Streams out the content in real-time
- Provides Higher performance and fault tolerance
- Java Script Rendering Executes the javascript code in web pages to create the final state of the page.
- Universal Parser: Apache Tika can deal with thousands of file formats, is used to discover links to the outgoing web resources and also to perform analysis on fetched resources.
You can find more information about Sparkler (workflows, features, …), please read these slides
Use Python with R
For the R package, I use a wrapper written in Python to speed up my development.
The wrapper can handle all the hard work for using OVH API including credential creation and requests signing
Step 1: install python 64 bits
The python wrapper works with Python 2.6+ and Python 3.2+.
The easiest way to get the latest stable release is to grab it from PyPI using pip.
$ pip install ovh
Next you need to use the reticulate package which provides an R interface to Python modules, classes, and functions. Yes, you can use Python module with R and it is useful.
$ install.packages("reticulate")
For example, this code imports the Python os module and calls some functions within it:
library(reticulate)
ovh <- import("ovh")
Functions and other data within Python modules and classes can be accessed via the $ operator
Use the API OVH
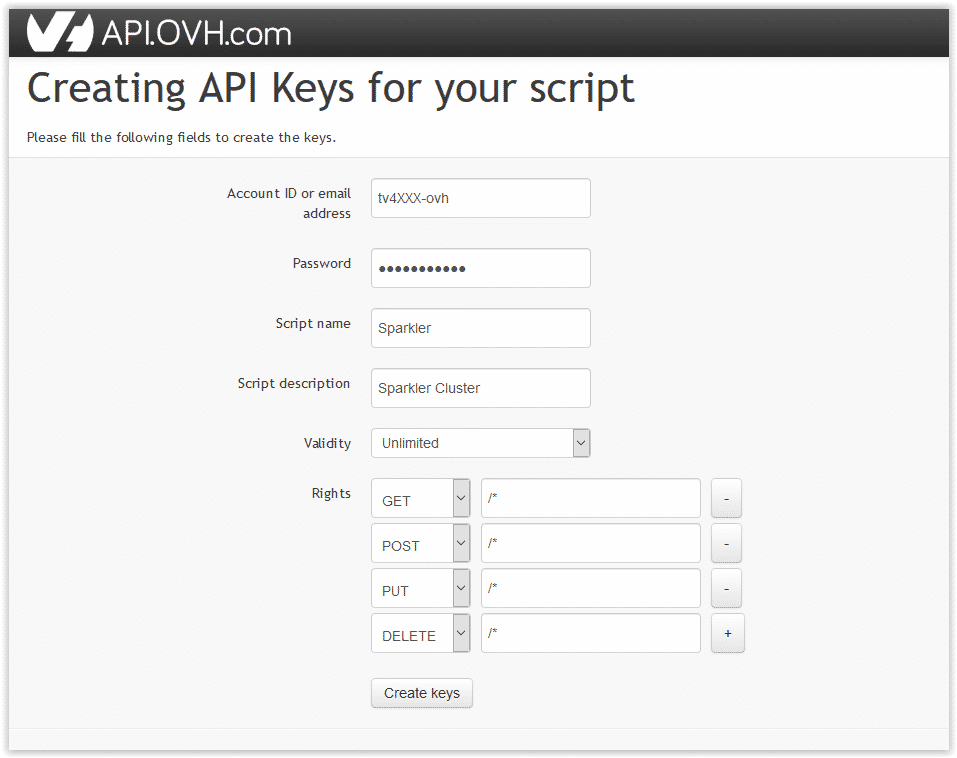
1. Create an application
To interact with the APIs, the SDK needs to identify itself using an application_key and an application_secret.
To get them, you need to register your application. Depending on the API you plan to use, visit:
https://api.ovh.com/createToken/index.cgi?GET=/*&POST=/*&PUT=/*&DELETE=/*
Once created, you will obtain an application key (AK) and an application secret (AS).
Use SSH key
When you launch an instance, you will not receive an email containing your details.
To gain access to your instance securely, you need to set up an SSH key.
This means that you can gain access:
- without having to remember a password
- with increased security
On Linux and Mac
On Windows ( it is the same procedure but you need to install: Git Bash http://gitforwindows.org/ )
Creating a key
Open up a terminal
Run the following command to generate a 4096 bit SSH key:
$ ssh-keygen -b 4096
You will be prompted for a location in which to save the private key:
Generating public/private RSA key pair.
Enter file in which to save the key (/home/user/.ssh/id_rsa):
Your identification has been saved in /home/user/.ssh/id_rsa.
Your public key has been saved in
/home/user/.ssh/id_rsa.pub.
The key fingerprint is:
0a:3a:a4:ac:d1:40:6d:63:6d:fd:d9:fa:d6:b2:e0:36 user@host
The key’s randomart image is:
+—[RSA 4096]—-+
| . |
| |
| . |
|. . . . |
|. .=.o .S. |
| =o.o. .. . |
|o + . . o .. |
|.. . oEoo . |
|o. .o+oo |
+—————–+
Use OpenStack with R
- Create a Client
You need to get appkey, appsecret, consumerkey
It is effortless, follow instructions here :
https://api.ovh.com/createToken/index.cgi?GET=/*&POST=/*&PUT=/*&DELETE=/*
client <- load_client(ovh,endpoint,application_key,application_secret,consumer_key)
- Create a Project
Start a new cloud project
projectId <- create_project(client,"Sparkler")$project
- Create a new Instance with OVH API
In OpenStack, a flavor defines the compute, memory and storage capacity of a virtual server also known as an instance.
A virtual machine image is a single file that contains a virtual disk that has a bootable operating system installed on it.
projectId: The id of your cloud project
flavorId: The id of your flavor
imageId: The id of your distribution
name: The name of your instance
region: The name of your datacenter
sshKeyId: The Id of your SSH Key
api_instance <- paste("/cloud/project/",projectId,"/instance",sep="")
res <- client$post(api_instance,
flavorId = flavorId,
imageId = imageId,
name = name,
region = reg,
sshKeyId = sshKeyId
)
- Create a Docker VM ( Thanks, Mark & Harbor): Logic Workflow
-
- get the available flavor where the name matching with the specific region
- get the active image where the name matching with “Docker”
- create the instance
create_docker <- function(projectId,name,reg,flavorName,sshKeyId) {
flavors <- get_flavors(projectId)
flavors <- select(filter(flavors,grepl(reg,region) & available==TRUE & name==flavorName),id)
flavorId <- toString(flavors[[1]])
images <- get_images(projectId)
images <- select(filter(images,grepl(reg,region) & status=="active" & grepl("Docker",name)),id)
imageId <- toString(images[[1]])
api_instance <- paste("/cloud/project/",projectId,"/instance",sep="")
res <- tryCatch({
myMessage('Creating an Instance with Docker', level = 3)
res <- client$post(api_instance,
flavorId = flavorId,
imageId = imageId,
name = name,
region = reg,
sshKeyId = sshKeyId
)
myMessage('Instance with Docker created', level = 3)
res
}, error = function(ex) {
myMessage("Error createVM : ",myAPIError(ex), level = 3)
})
res
}
- Create a Sparkler Docker
For creating a sparkler cluster, you need to specify :
– client: the name of the resource, provided by the client when initially creating the resource
– typeVM: the range of your cloud server ( s1-2, s1-4: https://www.ovh.co.uk/public-cloud/instances/prices/)
– regionVM: the name of datacenter: SBG3, BHS3, WAW1, UK1, DE1, GRA3
– sshPubKeyPath: your SSH public key that you have previously created
– sshPrivKeyPath: your SSH private key that you have already created
If the VM name exists but is not running, it starts the VM and returns the VM object
If the VM doesn’t exist, it creates the VM by using the create_docker function.
If the VM is running, it will return the VM object
library(RsparkleR)
ovh <- import_ovh()
client <- load_client(ovh,endpoint,application_key,application_secret,consumer_key)
sshPubKeyPath <- 'C:/Users/vterrasi/.ssh/id_rsa.pub'
sshPrivKeyPath <- 'C:/Users/vterrasi/.ssh/id_rsa'
vm <- sparkler.create(client,regionVM="UK1",typeVM="s1-4",sshPubKeyPath,sshPrivKeyPath)
2017-12-23 22:25:09> Library OVH ready
2017-12-23 22:25:09> OVH Client ready
2017-12-23 22:25:10> Sparkler exists :: 17d60332fe4c44cba48a511b18d052f0
2017-12-23 22:25:10> Get instances
2017-12-23 22:25:11> Docker VM Sparkler1 creating ::
2017-12-23 22:25:11> get SSH keys
2017-12-23 22:25:13> Get flavors
2017-12-23 22:25:14> Get Images
2017-12-23 22:25:16> Creating an Instance with Docker
2017-12-23 22:25:17> Instance with Docker created
2017-12-23 22:25:17> Docker VM checking Sparkler 1 IP :: 7a71acd0-0ee4-4bac-b405-c5cedf0053f2
2017-12-23 22:25:17> Get instance detail
2017-12-23 22:25:24> Docker VM Sparkler1 creating Wait 5s ::
2017-12-23 22:25:24> Get instance detail
2017-12-23 22:25:31> Docker VM Sparkler1 port 22 is closed Wait 5s ::
2017-12-23 22:25:38> Docker VM Sparkler1 port 22 is closed Wait 5s ::
2017-12-23 22:26:09> Docker VM Sparkler1 port 22 is open ! let's rock ::
Launch Crawl with Sparkler
Check if Docker exists and running
– If not, we create the docker with Sparkler with the “docker run” command
– If exists, we restart it
Next, we use “sparkler crawl” to inject URL parameters in Sparkler and launch a crawl.
Very important: Sparkler developers slow down the crawl to avoid getting blocked from the websites.
Top groups = number of hosts to fetch in parallel.
Top N = number of URLs in each website.
By default, it tries for 256 groups and 1000 URLs in each group
# START SPARKLER
sparkler.start(vm, debug)
# CRAWL CONF
url <- "http://data-seo.com"
pattern <- "data-seo.com"
topN <- 100
maxIter <- 10
topGroups <- 2
# START CRAWL
crawlid <- sparkler.crawl(vm, url, topN, topGroups, maxIter, debug=FALSE)
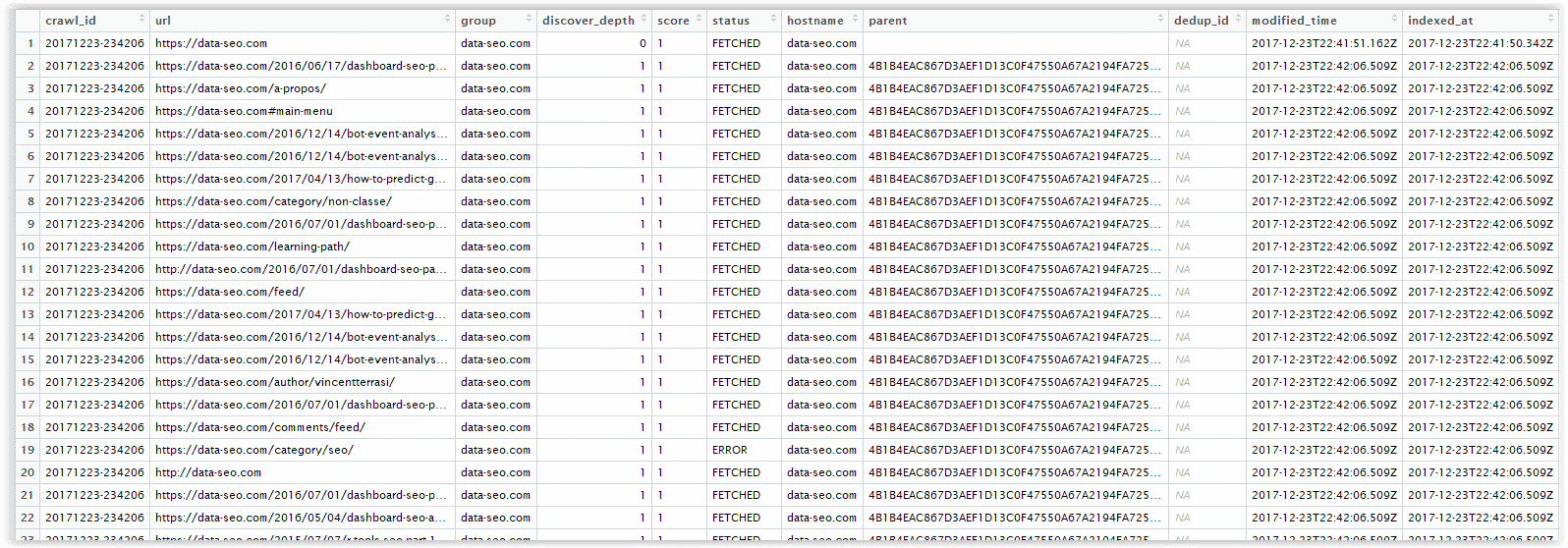
Use SolR API to read results with R
I create a function to get results from SolR server with interesting SEO features.
You can find a SolR tutorial here :
https://lucene.apache.org/solr/guide/7_2/solr-tutorial.html
url_solr <- paste("http://",vm$ip,":8983/solr/crawldb/query?q=*:*"
,"&rows=",limit,"&fl=crawl_id,url,group,discover_depth,score,status,"
,"hostname,parent,dedup_id,modified_time,indexed_at,last_update_at,"
,"fetch_status_code,fetch_depth,fetch_timestamp,content_type,signature,"
,"outlinks,"
,"og:title_t_md,dc:title_t_md,"
,"title_t_md,description_t_md,"
,"server_t_hd,content-type_t_hd",
sep="")
# get extracted txt
if (extracted==TRUE)
url_solr <- paste(url_solr,",extracted_text",sep="")
url_solr <- paste(url_solr,"&fq=hostname:",pattern,sep="")
url_solr <- paste(url_solr,"&fq=crawl_id:",crawl_id,sep="")
url_solr <- paste(url_solr,"&wt=csv",sep="")
res <- tryCatch({
read.csv(url(url_solr),header=TRUE,encoding="UTF-8",stringsAsFactors=FALSE)
}, error = function(ex) {
myMessage("Error : no solr", level = 3)
})
You will get this dataframe in RStudio :
Check state and stop your instance when it is finished
The crawl is very fast; I create three modes with different delays (in milliseconds) between two fetch requests for the same host
– default: 1000 ms
– fast: 500ms
– turbo: 100 ms
When there are no more unfetched URLs, you can delete your instance and keep your results in a dataframe.
My first test showed me that it is possible to crawl 5000 URLs / h in fast mode for 0.024€/H.
Of course, if you want to keep all history, you don’t need to delete your instance.
The variable crawl_id is a combination between the date of the day or hour of the day.
e.g. 20171228-140625 : 28 12 2017 14:06:25
crawlDF <- sparkler.read.csv(vm, pattern, crawlid, topUrls, extracted=FALSE)
checkAll <- sparkler.check(vm,pattern,crawlid,topUrls)
if (checkAll==TRUE) {
crawlDF <- sparkler.read.csv(vm, pattern, crawlid, topUrls, extracted=TRUE)
delete_instance(client, vm$projectId, vm$instanceId)
}
Use Banana to follow crawl in real-time
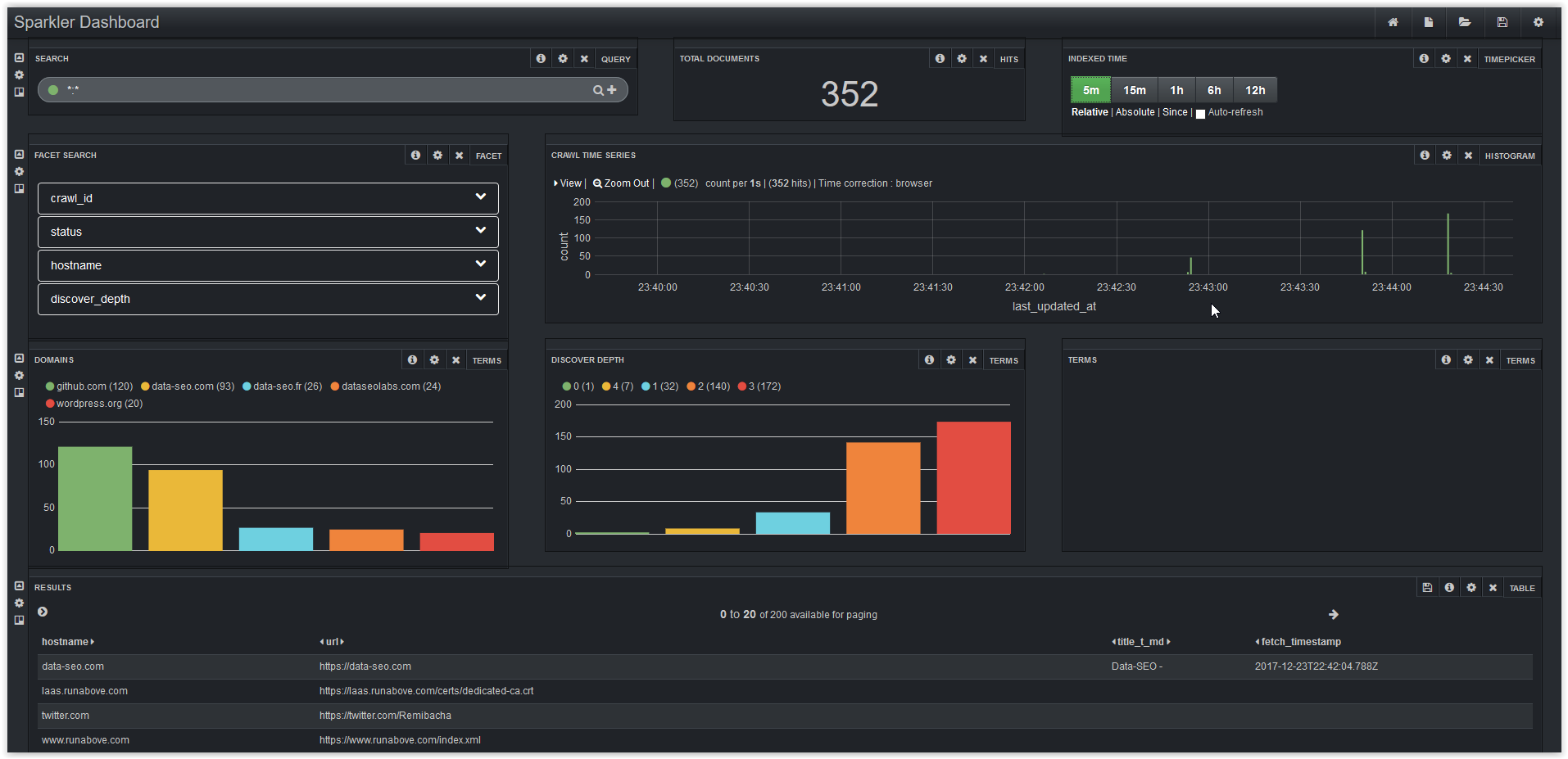
Banana is open source data visualization tool (based on Kibana) that uses Solr for data analysis and display.
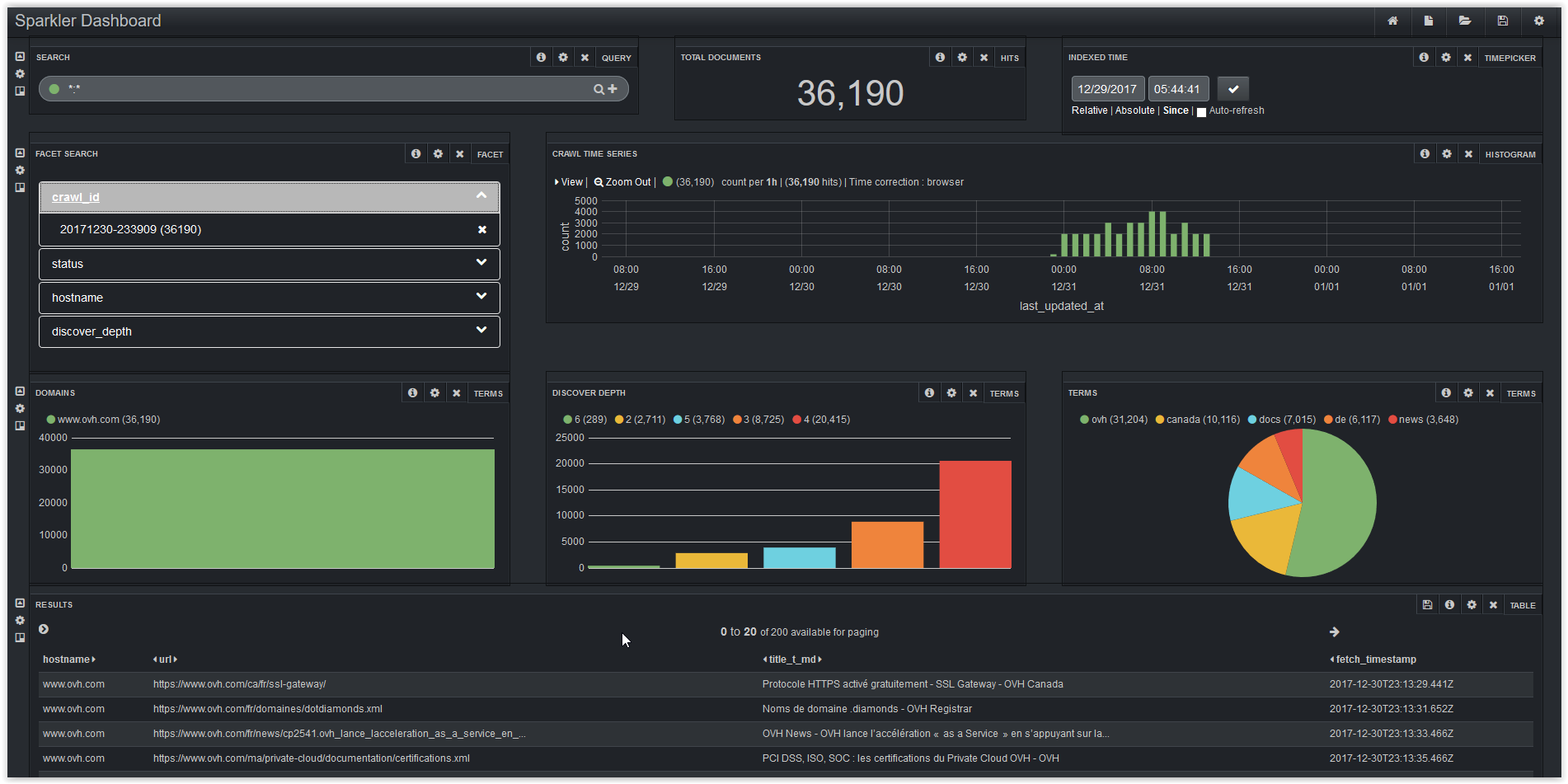
You can personalize all dashboards and get data about total documents, crawl time series, domains, discover depth and detailed results.
Bonus: Classify your URL & Dashboard
You want to learn how to use R packages, discover the DataSeo Labs training: https://dataseolabs.com/
Conclusion
It is just the part 1 and now, you can launch a powerful crawl with R + OpenStack + Sparkler. Sparkler is an excellent project created by USC Data Science and I am very proud to help them. If the “S” symbol means “Hope” in Kryptonian, the “S” symbol means “Sparkler” in SEO world!
You can find my R package on Github: https://github.com/voltek62/RsparkleR
Of course, you can see complete examples here: https://github.com/voltek62/RsparkleR-examples
Thanks to Aysun Akarsu : https://www.searchdatalogy.com/ and Mark Edmondson : http://markedmondson.me for re-reading.